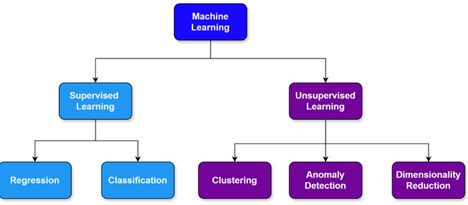
Machine Learning — Supervised and Unsupervised

Machine learning (ML) is a branch of artificial intelligence (AI) that empowers systems to learn from data and make predictions or decisions without explicit programming. ML algorithms analyze data patterns to generate informed predictions or classifications.
ML is broadly categorized into Supervised learning, Unsupervised learning, and Reinforcement learning. Common applications include recommendation systems, predictive analytics, fraud detection, speech recognition, sentiment analysis, machine translation, self-driving cars, and healthcare diagnostics. ML plays a crucial role in automating tasks and extracting insights from massive datasets.
In this article, we will focus on the first two types.
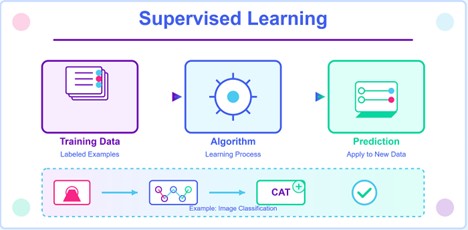
Supervised Learning: This is the most popular type of machine learning where it uses labelled data to make predictions. The algorithm uses input to output mapping. It learns from the training data (historical factual data) that has both the input data and the expected output. The algorithm eventually learns to take only the input and predict the output. Example: email spam detection, language translation, predict house price
Labeled Data: Refers to input data paired with the correct output value or answer. For example, in a dataset of 100 house prices and built-up areas, the “house price” constitutes the labeled data.
**Unsupervised Learning:**It is a type of machine learning where the model is trained on data without the labeled data. Instead of learning from labeled data as we saw in Supervised, here the model tries to identify patterns and structures within the input data on its own. The algorithm has to find some of pattern or structure in the input data. Example : Customer Segmentation, Market Analysis, Grouping Employees
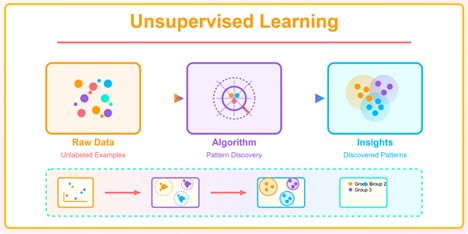
Here are common types of Unsupervised learning:
Clustering: In this type, the algorithm takes the input data without labels and group them into “clusters” based on their characteristics. Example: Grouping customers based on purchasing behavior, grouping patients with similar conditions or behaviors.
Anomaly Detection: In this type, the algorithm tries to find unusual patterns or outliers in data that do not meet the expected behavior. Example: Very commonly used for Fraud detection in financial services to identify unusual transactions, used in network security to monitor suspicious activity or in healthcare to defect unusual patterns
Dimensionality Reduction: In this type, the algorithm reduces the number of input variables (or features) in the dataset without losing any important information. This can help the performance of machine learning models when dealing with high dimensional input data. Example: Used to compress images while preserving the features, identify key factors influencing stock price and so on.
Conclusion
This article has provided a foundational understanding of the two primary types of machine learning: Supervised and Unsupervised learning. Future articles will delve deeper into specific algorithms and techniques within these categories.
Happy Learning!